背景
接到了线上机器的报警,登上服务器,发现是Java进程挂了,看日志报了OOM:
1
java.lang.OutOfMemoryError: Java heap space
问题描述
内存溢出,那当然是看dump文件了。这里推荐大家在产线机器上都加上JVM参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={path}/{to}/{dump},这样,JVM在OOM的时候,会自动做一个内存dump,相当于保存现场。
拿到dump文件,放到MAT里面分析,以下是部分截图:
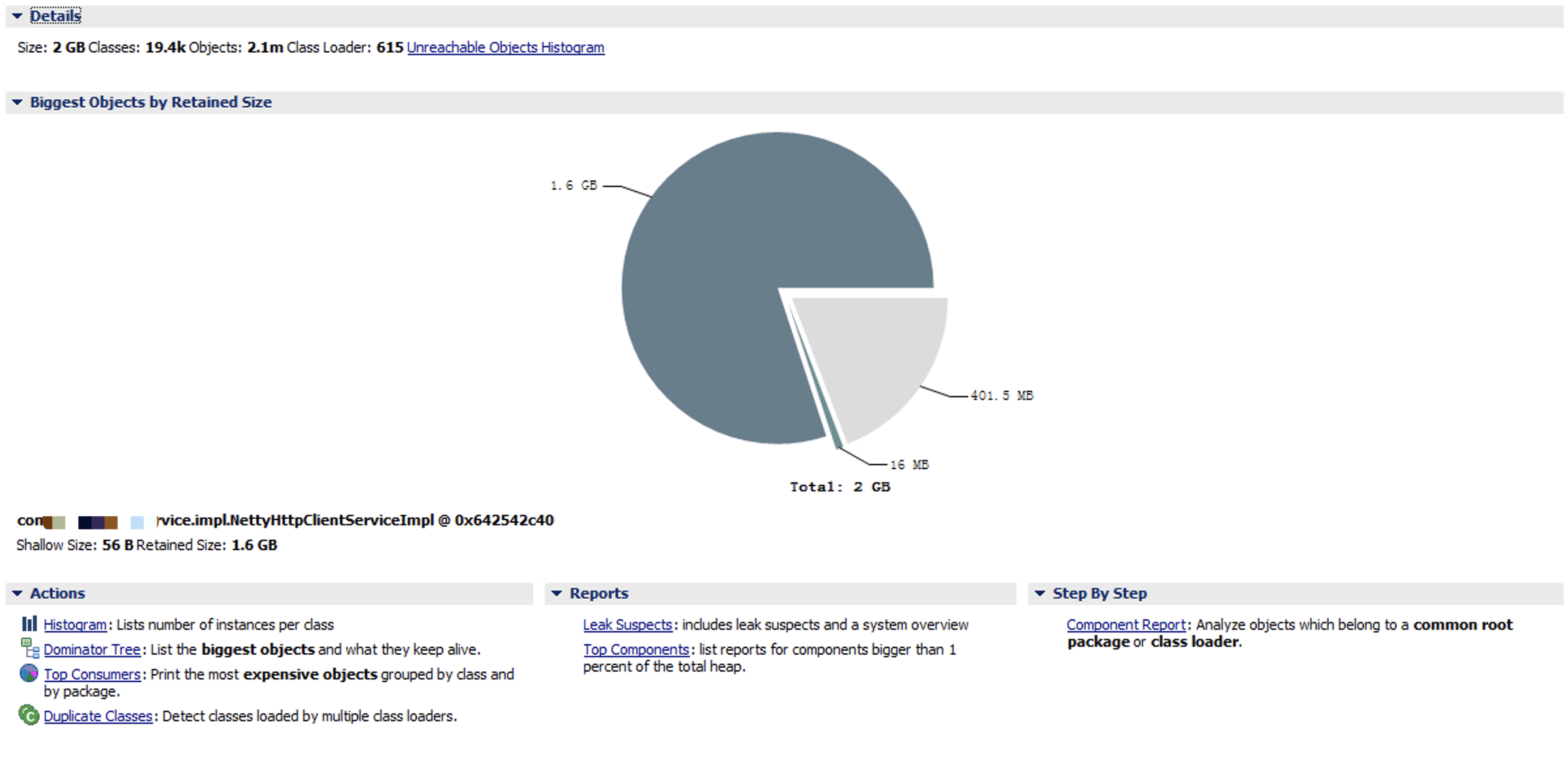
不看不知道,一看吓一跳:有一个class(包括其reference)竟然占据了1.6G的内存!
这个类叫NettyHttpClientService,是工程里面用来提供异步Http服务的,其实就是对Netty做了一层包装。这个类上线已久,之前工作得很好没出什么问题。最近一次上线,也没有对这个类做什么改动,只是新增了一处调用它的地方。
需要进一步挖掘NettyHttpClientService这个类。
问题分析
继续分析内存占用情况,发现其大头是一个ConcurrentHashMap,里面的每个node都占用了10M-20M的空间,而这个Map里面,已经存在了135个node:
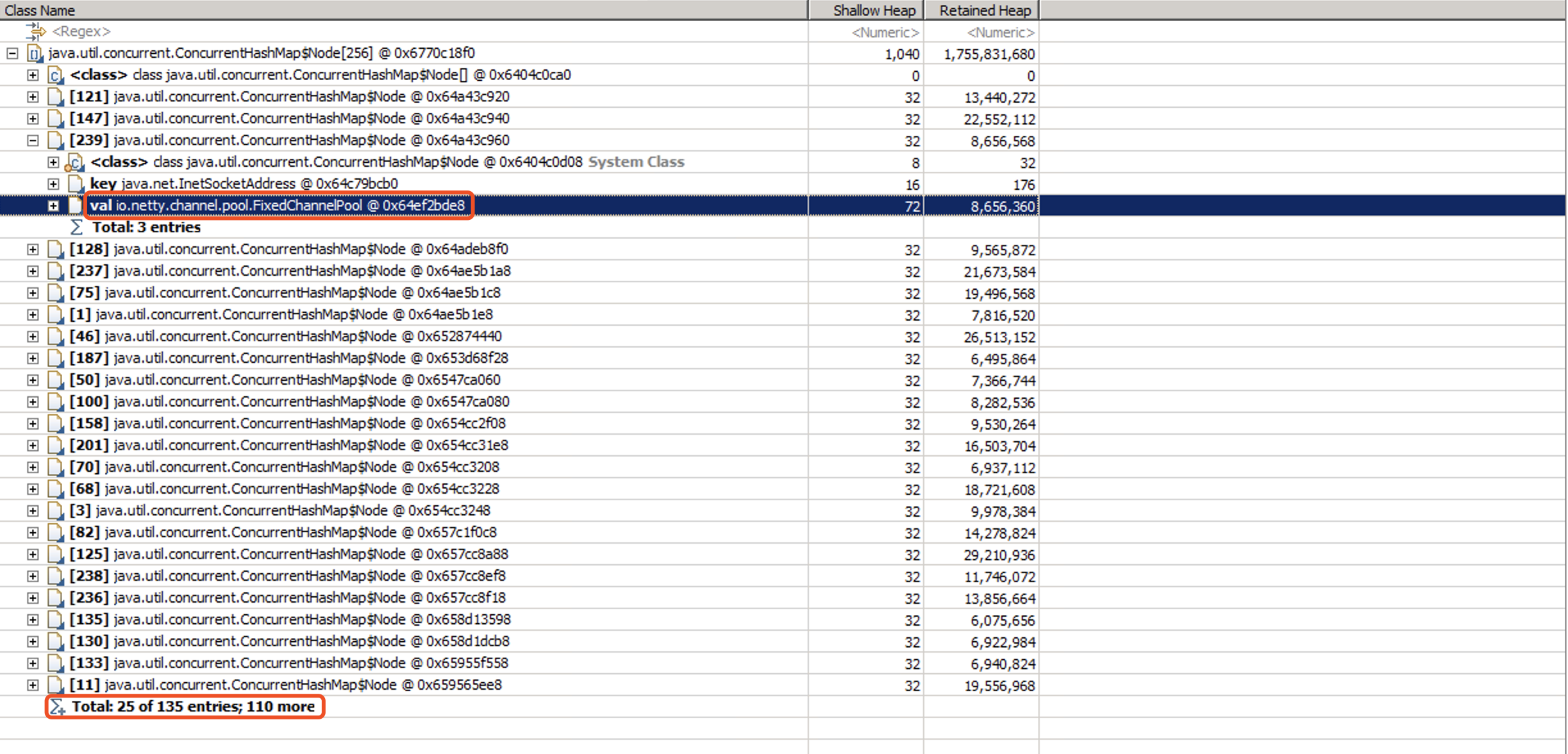
看来还得去代码里面寻找真相。找到源头,以下是简化版的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
public class NettyHttpClientServiceImpl implements NettyHttpClientService, DisposableBean {
// channelPoolMap是一个InetSocketAddress与ChannelPool的映射关系
private AbstractChannelPoolMap<InetSocketAddress, FixedChannelPool> channelPoolMap = new AbstractChannelPoolMap<InetSocketAddress, FixedChannelPool>() {
// 构建新的大小为200的ChannelPool
@Override
protected FixedChannelPool newPool(InetSocketAddress key) {
return new FixedChannelPool(bootstrap.remoteAddress(key), new NettyHttpPoolHandler(), 200);
}
};
// NettyHttpClientService的入口,参数是请求体RequestEntity,成功回调successCallback,失败回调errorCallback
@Override
public Promise<SimpleResponse> get(RequestEntity bean, Consumer<SimpleResponse> successCallback, Consumer<Throwable> errorCallback) throws PlatformException {
final URL url= new URL(bean.getUrl());
// 构造远程服务的InetSocketAddress
InetSocketAddress address = new InetSocketAddress(url.getHost(), url.getPort() == -1 ? url.getDefaultPort() : url.getPort());
Promise<SimpleResponse> promise = newPromise();
// 从ChannelPool中获取channel
acquireChannel(address).addListener(future -> {
if (!future.isSuccess()) {
promise.tryFailure(future.cause());
return;
}
try {
// 发送request
send(bean, (Channel) future.get(), promise);
} catch (Exception e) {
promise.tryFailure(e);
}
});
// 回调
promise.addListener(future -> {
if (future.isSuccess()) {
successCallback.accept(future.get());
} else {
errorCallback.accept(future.cause());
}
});
return promise;
}
private Future<Channel> acquireChannel(InetSocketAddress address) {
Promise<Channel> promise = newPromise();
// 找到address对应的那个ChannelPool,再从ChannelPool中获取一个Channel
channelPoolMap.get(address).acquire().addListener(future -> {
if (future.isSuccess()) {
Channel channel = (Channel) future.get();
promise.trySuccess(channel);
} else {
promise.tryFailure(future.cause());
}
});
return promise;
}
}
ChannelPool的理念类似于线程池和数据库连接池,为了减少Channel频繁创建与销毁的开销。不难理解,上述设计意在为每个远程服务维护一个ChannelPool,这样每个服务之间可以做到隔离,互不影响。
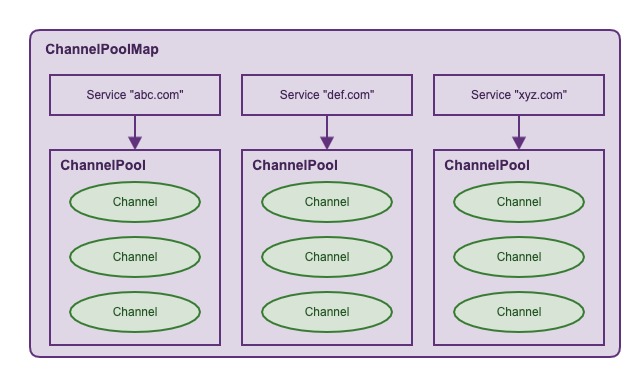
代码的大体逻辑很简单,根据请求的地址,获取对应的ChannelPool,然后从中获取一个Channel来进行Http交互。理论上来说,程序与几个Http服务有交互,那么就会创建几个ChannelPool(像abc.com/v1/api1,abc.com/v1/api2,abc.com/v1/api3都属于abc.com这个服务)。之前,程序只会去请求4个Http服务,最近一次上线新增了1个,所以目前总共应该是5个ChannelPool,但是从MAT的分析结果来看,产线上存在了135个ChannelPool!
没有其他外部作用的情况下,产线运行出现问题,最先应该怀疑新上线的功能,所以盯上了NettyHttpClientService新增的一处调用(feature-a.nf.com)。
channelPoolMap是用InetSocketAddress作为key的,难道feature-a.nf.com对应的InetSocketAddress会存在多个值?我们尝试多次运行InetAddress.getByName("feature-a.nf.com"),果然每隔一段时间,域名所对应的ip就会发生变化,导致channelPoolMap对这个服务创建了多个ChannelPool。
为什么会存在这么多个ChannelPool的原因总算是找到了。但是,为什么每个Pool的内存占用会这么高达到十几二十兆呢?继续翻看代码以及MAT的分析报告,找到了原因:
1
2
3
4
5
6
7
8
9
10
private void send(RequestEntity bean, Channel channel, Promise<SimpleResponse> promise) {
// 将entity放到channel的attribute中作为上下文
channel.attr(REQUEST_ENTITY_KEY).set(bean);
HttpRequest request = createHttpRequest(bean);
QueryStringEncoder getEncoder = new QueryStringEncoder(String.valueOf(new URI(bean.getUrl())));
for (Entry<String, String> entry : bean.getHeaders().entrySet()) {
getEncoder.addParam(entry.getKey(), entry.getValue());
}
channel.writeAndFlush(request);
}
在真正发送请求的send()方法里,把请求体RequestEntity作为了一个channel的attribute,所以只要Channel不释放,那么RequestEntity就不会被GC。而这个RequestEntity不仅会存放请求的信息如请求头,目标地址等,还会存放请求返回值。该API的ResponseBody大小一般是几十K。
假设RequestEntity最终大小是50k,每个ChannelPool的大小是200,共有135个ChannelPool,那么无法被GC的内存大小为:50k * 200 * 135 = 1.35G,这就是内存泄漏的元凶。
至于为什么需要将RequestEntity放到channel的attribute中,是因为当遇到返回码类似401或者302的时候要处理重发的逻辑,需要保存请求的上下文。
而为什么feature-a.nf.com会解析对应这么多个IP,怀疑因为这个服务是做的4层负载均衡。
问题解决
既然找到了root cause,解决起来就简单了。两点:
- 用
String类型的hostname作为channelPoolMap的key,防止为一个服务创建多个ChannelPool。 - 在
ChannelPool的release()方法中,释放Channel对RequestEntity的引用(清理attribute),避免内存泄漏。
总结
在使用常驻内存的类时,需要小心是否有内存泄漏的情况。如本例ChannelPool中的Channel使用完毕是不会释放的,所以要谨慎使用Channel的Attribute。正如ThreadLocal中引入弱引用一样,就是因为ThreadLocal变量通常是常驻内存的,而且由它导致的内存泄漏常常更隐蔽,所以使用弱引用可以很好地避免绝大多数潜在的OOM危机。
