背景
监控是系统的重要模块,我们给产线的 Redis 机器配置了全方位的监控,包括机器性能指标测试以及 Redis 服务测试等等。今天收到了 PagerDuty 告警,报告说 Redis 服务间歇性异常。
问题描述
Redis 是一个集群,三主三从,每个节点各配置了一个监控,监控的测试逻辑大致是,用 INFO,CLUSTER SLOTS,CLUSTER NODES 等命令查看节点以及集群的基本信息是否正常,然后给主节点(master) set 一个 dummy key,看是否在规定时间内能同步到从节点(slave)。
报警来自于一台从节点,观察了一下报错信息:
Redis is loading the dataset in memory
问题定位
上述提示可能在以下两种情况出现:
- 当主节点启动的时候
- 当从节点跟主节点重连进行全量数据同步的时候
也就是说,当数据集(dataset)还未被全部加载进内存中时,如果客户端给 Redis 发送命令,则会收到上述错误提示。考虑到报错的是一台从节点,所以是第二种情况:从节点频繁跟主节点重连。
连上告警的节点,执行 INFO MEMORY,连续几次的关键信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
redis> info memory
# Memory
used_memory_human:53.27M
used_memory_peak_human:9.68G
used_memory_peak_perc:0.54%
maxmemory_human:16.00G
redis> info memory
# Memory
used_memory_human:2.19G
used_memory_peak_human:9.68G
used_memory_peak_perc:22.63%
maxmemory_human:16.00G
redis> info memory
# Memory
used_memory_human:4.13G
used_memory_peak_human:9.68G
used_memory_peak_perc:42.69%
maxmemory_human:16.00G
redis> info memory
# Memory
used_memory_human:7.15G
used_memory_peak_human:9.68G
used_memory_peak_perc:73.88%
maxmemory_human:16.00G
redis> info memory
# Memory
used_memory_human:9.50G
used_memory_peak_human:9.68G
used_memory_peak_perc:98.08%
maxmemory_human:16.00G
直观可以看到,节点在持续加载数据直到内存升到 9.5G 左右,过程持续大约一分钟。稳定一小段时间之后,又重复数据加载的过程。
问题排查
首先我们考虑是不是节点所在的物理机有问题,于是用 CLUSTER FAILOVER 强制做了主从切换,观察一段时间发现,原先告警的节点升为主节点之后状态就正常了,而原先正常的主节点变为从节点之后开始告警。说明问题与机器无关,跟主从关系有关。
我们开始将关注点主从复制,有一个细节:Redis 节点的最高内存占用是 9.68G,而按照之前我们的印象应该是 5G 左右,于是我们去查看了 Redis 的内存监控图表:
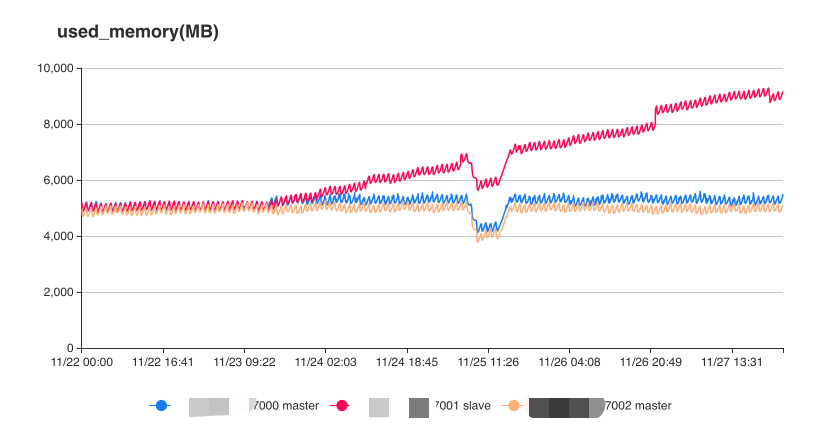
可以看到,从 23 号开始,目标节点的内存开始出现异常升高,但因为每个节点的内存限制是 16G,所以内存指标并没有报警,反而是服务先出现了异常。
23 号正好是我们上线的日期,所以问题大概率与新功能有关了。查了一下,这次确实新增了一些 Redis 的缓存数据,格式大概是 hash_service_statistic:{serviceId},记录的是 service 的一些统计数据。不过按道理数据会根据 serviceId 不同而被打散,但为什么新增的数据似乎都被分配到同一个节点上了呢?原来产线上的 serviceId 值未被初始化,都是 0,这是一个未开发完全的功能,此次上线的只是数据聚合的部分。所以图中显示的增长的大约 5G 数据,其实都是来自于同一个 key hash_service_statistic:0,妥妥的 Big Key 了。
由于 key 太大,导致了对应节点数据复制缓慢,在 TPS 较高的情况下,从节点间断性重连,并且因为数据落后主节点过多会进行全量数据同步(默认的 repl-backlog-size 是 1MB),导致出现 Redis is loading the dataset in memory。
问题解决
将 Big Key 删除,然后将 serviceId 初始化一遍。
1
2
3
4
redis> del hash_service_statistic:0
-> Redirected to slot [7924] located at *.*.*.*:7001
(integer) 1
(43.94s)
key 的删除都花了 43.94 秒…
总结
又是一个深刻的教训:线上出问题,很多时候与新上的 feature 有关。 用 Redis Cluster 做缓存时要谨防 Big Key 的出现,尽量将 Key 打散在各个节点中。 产线的服务需要配置好全方位的监控,合理的监控可以在真正严重的问题出现之前就给予告警。
参考
ERROR: LOADING Redis is loading the dataset in memory
Redis Replication
